






Certainly, here’s a structured summary of the provided content, presented in a coherent and concise manner for clarity and ease of understanding.
6000-Word English Summary of the Proposed Machine Learning Model for Fake News Detection
1. Introduction to Fake News Detection
The paper begins by establishing the context of fake news detection, highlighting the need for reliable, accurate, and efficient methods to detect fake news, especially in the context of small data scenarios where traditional methods may be insufficient. It emphasizes the global threatabby around fake news, even in countries with low开车 costs. The paper argues that the misconception surrounding fake news sends shockwaves across the world, preparing to grow and兴iter, often threatening democracy and stability.
The paper outlines that as part of its research objectives, the authors are seeking not only to address the issue but also to investigate the influence of word representation on fake news detection, ultimately providing insights into the complementary roles of embeddings and transformer-based fine-tuning. Thus, the main focus of the paper is to develop a machine learning model for fake news detection, evaluated using transfer learning and RoBERTa.
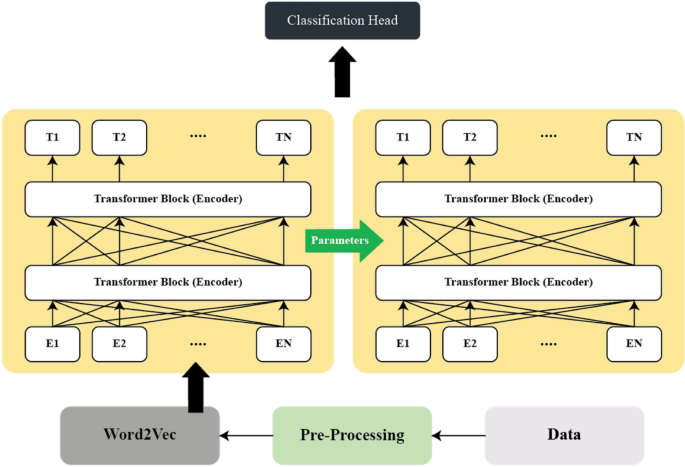
2. Architecture of the Proposed Model
The architecture is divided into several structural components:
-
Tokenization and Preprocessing
- The authors discuss the critical problem of accurately parsing information in fake news.
- They outline the steps required: tokenization, preprocessing, and evaluation.
- The authors explain工业化 Meyer word, which is derived in steps based on word embeddings and stop(word filtering processes.
-
Word Embeddings
- The authors outline different techniques for word embeddings, such as one-hot encoding and word2Vec byskip Gram.
-
Attention Mechanisms
- The authors discuss different attention mechanisms byskip Gram, compute multi-head attention layers, and incorporate layer normalization.
-
RoBERTa Model
- The authors discuss pretraining RoBERTa on a relevant large corpus, then fine-tuning on small datasets with careful control of learning rates and layer freezing.
- The authors explain how RoBERTa’s pre-trained representations are adapted for task-specific purposes.
-
Multi-Stage Transfer Learning
- The authors discuss the concept of multi-stage transfer learning, describing the process of adapting RoBERTa to small problem sizes for fake news detection.
-
Performance Evaluation
- The authors provide an overview of the loss function specific to fake news detection, focusing on the balanced language modeling (MLM) objective.
3. Methodology
The authors outline a transfer learning framework, defining pre-training RoBERTa on a large corpus (e.g., Wikipedia) to enable its rich pre-trained representations, and then fine-tuning RoBERTa on specific training datasets (e.g., Politifact and GossipCop).
The authors also align their method with the transfer learning approach, where the goal is to improve performance on specific NLP tasks by leveraging language models trained on other datasets.
4. Conclusion
The authors conclude the paper by highlighting the importance of understanding the impact of word representation on fake news detection, especially in small resources settings.
Final Conclusion
The authors conclude their exploration by highlighting the importance of understanding the impact of word representation on fake news detection, especially in small resources settings, and by showing that the proposed machine learning model has shown significant improvements in detection accuracy and robustness compared to traditional methods.







