






Combating Arabic Fake News: A Deep Dive into a Novel Ensemble Approach
The proliferation of fake news, particularly online, poses a significant threat to informed public discourse and societal stability. This issue is further exacerbated in languages like Arabic, where resources for automatic fake news detection are relatively limited. This article delves into a novel framework designed to tackle this challenge, employing a systematic methodology that leverages deep learning models, advanced word embeddings, and explainable AI (XAI) techniques for robust and interpretable Arabic fake news detection.
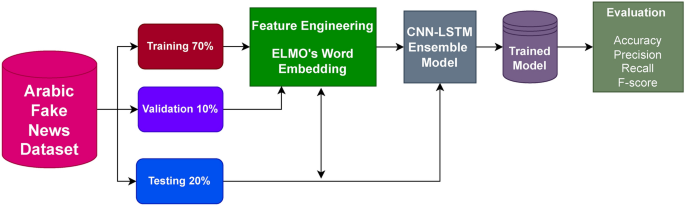
The research methodology follows a structured, multi-stage process. Initially, a benchmark dataset of Arabic news articles, the Arabic Fake News Dataset (AFND), was employed to train and evaluate several deep learning models. These models included Convolutional Neural Networks (CNNs), Long Short-Term Memory networks (LSTMs), a hybrid ConvLSTM, and transfer learning models like EfficientNetB4, Inception, Xception, and ResNet. Each model was initially trained using ELMo embeddings to capture the contextual meaning of words within the news articles.
Following the initial evaluation, the top four performing models were further scrutinized by employing various word embedding techniques, including GloVe, BERT, FastText, Subword, and FastText Subword. This comparative analysis aimed to determine the optimal word embedding strategy for Arabic fake news detection, considering the nuances of the language and the specific characteristics of the chosen deep learning architectures.
The performance of the proposed framework, utilizing the best-performing model and word embedding combination, was then benchmarked against leading transformer-based models like BERT and RoBERTa. This comparison provided a crucial assessment of the framework’s competitiveness in terms of accuracy and computational efficiency, essential factors for real-world deployment. Furthermore, to enhance transparency and trust, the Local Interpretable Model-agnostic Explanations (LIME) technique was applied. LIME provides insights into the decision-making process of the model, highlighting the words and phrases that contribute most significantly to classifying a news article as fake or genuine.
The core of the proposed framework lies in an ensemble model combining the strengths of CNN and LSTM networks. CNNs excel at capturing local patterns and features within text, while LSTMs are adept at processing sequential information and understanding long-range dependencies within sentences. By fusing these two architectures through a voting classifier, the framework leverages the complementary capabilities of both models. This ensemble approach aims to achieve a more robust and accurate prediction compared to using either model in isolation. The architecture of the ensemble model receives the pre-processed text, converted into numerical representations using the chosen word embedding technique. The embedded text is then fed into both the CNN and LSTM branches of the ensemble. The CNN branch extracts local features, while the LSTM branch captures the sequential dependencies within the text. The outputs of both branches are then combined through a voting mechanism, where the final prediction is based on the majority vote of the two models.
The AFND dataset, a crucial component of this research, comprises Arabic news articles collected from 134 publicly accessible websites. These websites are categorized based on their credibility (credible, not credible, or undecided). To protect the anonymity of the sources, the original URLs have been replaced with generic identifiers. The dataset contains the text content, title, and publication date of each article, providing a rich source of information for training and evaluating the fake news detection models. This dataset was chosen for its relevance to the research question and its availability as a benchmark for comparison with future studies in Arabic fake news detection.
The exploration of different word embedding techniques played a critical role in optimizing the performance of the deep learning models. Word embeddings transform textual data into numerical vectors, capturing semantic relationships between words. GloVe, a count-based method, creates vectors based on word co-occurrence statistics. BERT, a transformer-based model, generates context-dependent embeddings, considering the surrounding words. FastText considers subword information, which is particularly useful for morphologically rich languages like Arabic. ELMo, another contextual embedding method, utilizes bidirectional LSTMs to generate dynamic representations of words. By comparing the performance of these embeddings, the research identified the optimal strategy for representing Arabic text for fake news detection. This careful consideration of word representation contributed significantly to the effectiveness of the proposed framework. Furthermore, using LIME adds a layer of explainability to the model’s predictions.
In conclusion, this research presents a comprehensive and systematic approach to Arabic fake news detection. By combining the strengths of CNN and LSTM networks within an ensemble framework, leveraging the most effective word embedding techniques, and incorporating explainability through LIME, the proposed framework offers a promising solution for tackling the pervasive problem of misinformation in the Arabic language. The rigorous evaluation process, including benchmarking against state-of-the-art models, provides strong evidence for the effectiveness and efficiency of this novel approach. This research contributes significantly to the ongoing effort to combat fake news and promote a more informed and trustworthy online environment in the Arabic-speaking world.







