






Unmasking Deception: A Multifaceted Approach to Detecting Fake News in COVID-19 Tweets
The proliferation of misinformation, particularly surrounding critical events like the COVID-19 pandemic, has highlighted the urgent need for robust fake news detection mechanisms. This article details a comprehensive research methodology employed to analyze tweets related to COVID-19, aiming to discern sentiment, emotion, and ultimately, the veracity of the information shared. The approach involves a combination of lexicon-based sentiment analysis, emotion extraction, and sophisticated machine learning models, including deep learning, to achieve a nuanced understanding of fake news propagation on social media.
The foundation of this research rests on a publicly available dataset comprising 10,700 English tweets tagged with COVID-19 related hashtags. This balanced dataset, previously utilized in other studies, contains roughly equal numbers of real and fake news tweets. The tweets were manually annotated for veracity, with fake news identified through fact-checking websites and social media platforms, while real news tweets were sourced from official and verified channels. This meticulous data collection process ensures the reliability and validity of the research findings.
Before applying the analytical models, the tweet text underwent rigorous preprocessing. This involved removing non-alphabetic characters, converting text to lowercase, eliminating stop words (common words like "a," "the," "is," which offer limited informational value), and lemmatization (reducing words to their base form). This preprocessing step is crucial for improving the accuracy and efficiency of the subsequent analytical stages by focusing the models on the most meaningful elements of the text. The preprocessed text was then converted into numerical data using the scikit-learn ordinal encoder, making it suitable for machine learning algorithms.
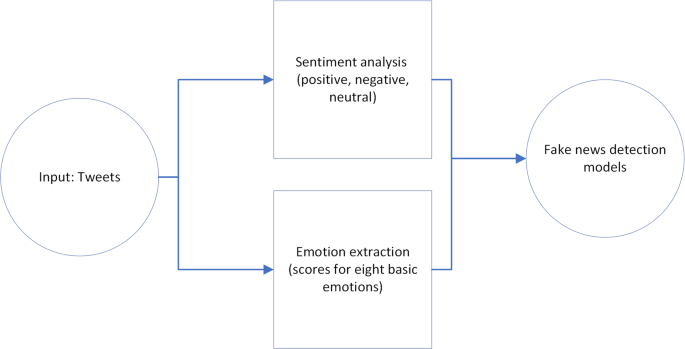
The research followed a structured, multi-stage process. First, sentiments and emotions embedded within the tweets were extracted. Subsequently, the observed differences in sentiment and emotion between real and fake news tweets were leveraged to train fake news detection models. This process allowed for a deeper understanding of the emotional and psychological factors that contribute to the spread of misinformation.
Sentiment analysis, a crucial component of the methodology, was conducted using three established lexicons: Vader, TextBlob, and SentiWordNet. Vader, specifically designed for social media text, TextBlob, a Python library for natural language processing, and SentiWordNet, a lexical resource for opinion mining, were employed to classify tweets as positive, negative, or neutral. A comparative analysis of these lexicons was performed to determine the most effective tool for this specific task. The performance of each lexicon was assessed based on manually labeled sentiments, and Vader demonstrated superior performance in distinguishing between real and fake news tweets based on sentiment. The analysis revealed a clear trend: fake tweets tended to exhibit more negative sentiment, while real tweets leaned towards positive sentiment.
Beyond sentiment analysis, the research also explored the emotional landscape of the tweets using the NRC emotion lexicon. This lexicon identifies eight core emotions – joy, trust, fear, surprise, sadness, anticipation, anger, and disgust – within text data. By analyzing the distribution of these emotions, the research aimed to uncover emotional patterns associated with fake news. The findings corroborated the sentiment analysis, showing that fake tweets were more likely to evoke negative emotions like fear, disgust, and anger, while real tweets expressed more positive emotions such as anticipation, joy, and surprise.
The culmination of this research involved applying a range of machine learning models to detect fake news. Three established machine learning classifiers – Random Forest, Naïve Bayes, and Support Vector Machines (SVM) – and a cutting-edge deep learning model, BERT (Bidirectional Encoder Representations from Transformers), were employed. These models were trained on the preprocessed tweet data, incorporating both the text and the extracted sentiment and emotion features. The performance of the models was then evaluated by comparing their accuracy in classifying tweets as real or fake.
To assess the impact of incorporating emotions, the models were trained both with and without the emotion features. The results demonstrated that including emotion scores as features significantly enhanced the accuracy of both the machine learning and deep learning models in detecting fake news. This underscores the crucial role emotions play in the dissemination and reception of misinformation. By capturing these nuanced emotional cues, the models could better differentiate between real and fake news.
In conclusion, this research showcases a comprehensive and effective methodology for fake news detection by integrating sentiment analysis, emotion extraction, and advanced machine learning techniques. The findings emphasize the significance of emotional content in differentiating fake news from credible information. This research contributes valuable insights to the ongoing fight against misinformation and provides a robust framework for developing future fake news detection tools. The incorporation of emotion analysis adds a new dimension to the field, enabling a deeper understanding of the psychological drivers behind the spread of fake news and paving the way for more sophisticated and accurate detection mechanisms.







